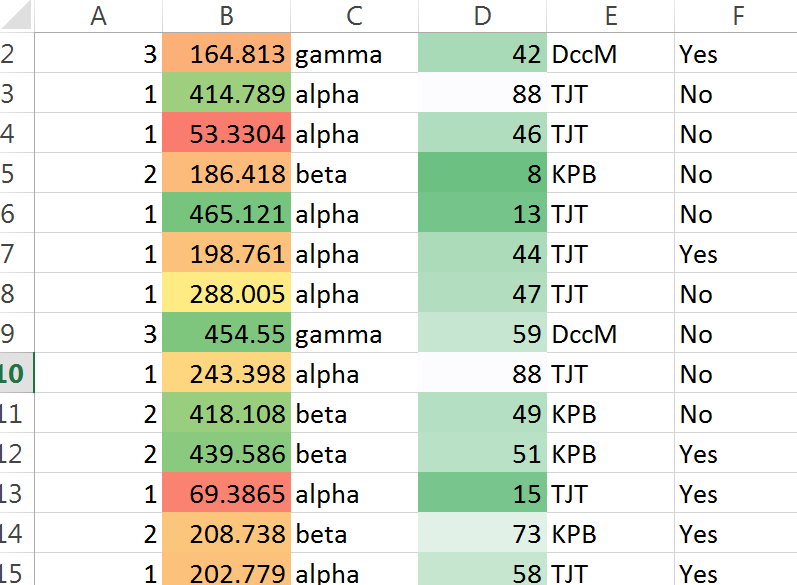
Large data sets – not the most inspiring of titles, but one which we teachers of A Level maths will become increasingly familiar over the next few weeks and months.
A Level maths is changing, but two plus two remains four, most of the content that is in the current A Level syllabus is in the new syllabus, to be taught from September ’17. It’s place in the syllabus may have changed – i.e. a topic that currently appears in Core 3 may now find itself in AS maths and be taught in the lower sixth/first year of A Level, but there is nothing that will be too unfamiliar to today’s teacher or today’s student.
Except for large data sets.
Candidates are to be familiar with one or more specific large data sets, to use technology to explore the data set(s) and associated contexts, to interpret real data presented in summary or graphical form, and to use data to investigate questions arising in real contexts.
… and that is new.
So its time to start thinking about large data sets, what they are, how we will teach with them, how they will impact on the exams…
The boards have, helpfully, published the large data sets that they will be using, and I’ve put copies of them here:
Further down this page you can see some sample questions from the boards that relate to the large data sets.
So what is to be expected of the student in the exam?
I must add a caveat that I am crystal ball gazing, and this is just my own view and not that of any board, but it seems that students won’t have to have whizzy excel skills to manipulate the data in the exam. They will be examined on this part of the syllabus like all others: in questions on paper in an exam hall, no computerisation of the exam. They could succeed on these elements of the exam with no knowledge of how to use Excel (or any other package) to manipulate data. But, as I will begin to explore below, manipulating the data with Excel (or similar) in lessons or homework will help them develop a good knowledge of the structure and content of the data, and this is important.
Have a look at this sample question from OCR, in particular part ii):
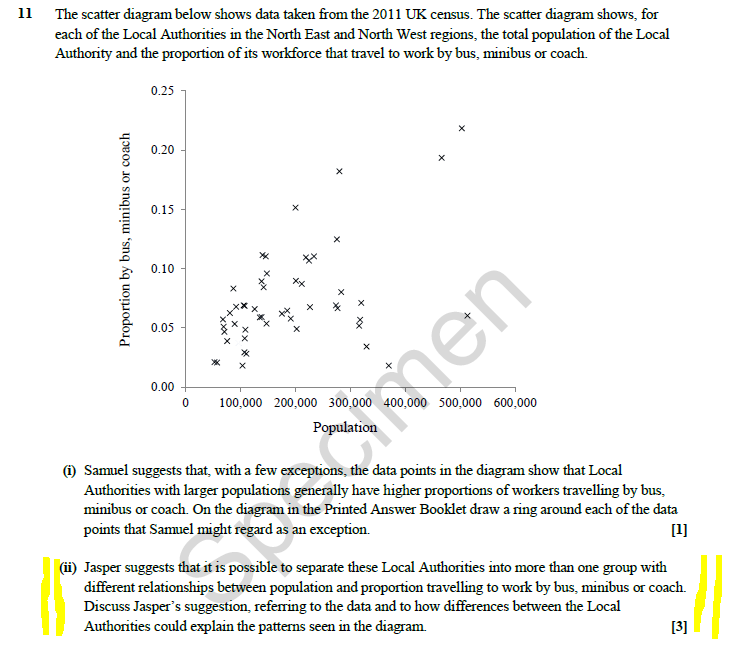
OCR Large Data Set Sample Question
To effectively answer this you need to know that the data set contains different regions with different geographical characteristics, and the differences between, say Unitary Authority and a Metropolitan Borough and how the provision of public transport within different areas varies. (If you don’t believe me, have read of the mark scheme below.)
I must confess, I am a little uneasy with this – are we examining mathematical skills or geographical knowledge?
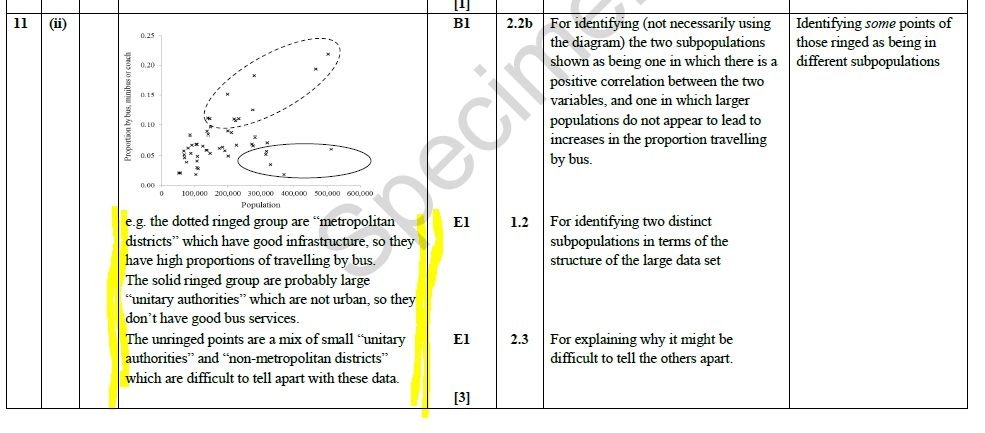
OCR data set sample question answer
After years of staff shortages meaning Geography teachers have ended up teaching maths it now seems that we maths teachers are going to have to do a bit of Geography teaching!
However, we must do the best for our students and so we must familirise them with the nature, structure and content of the data sets. To do this I will look at how I can incorporate them into teaching as many aspects of the syllabus as possible. For example, I will get students to calculate the Standard Deviation of all, or a sample of, the data set – and not just using the single Excel formula. But that’s a post (or several) for another day.
This post was hopefully a brief introduction to Large Data Sets. Download the files for yourself, have a play and a think about how you might use them. As ever, I’d be delighted to hear your suggestions. And have a look at another couple of sample questions designed to examine the students familiarity with, and ability to explore and manipulate, large data sets.

EdExcel sample Large Data Set question

EdExcel large data set sample question answer
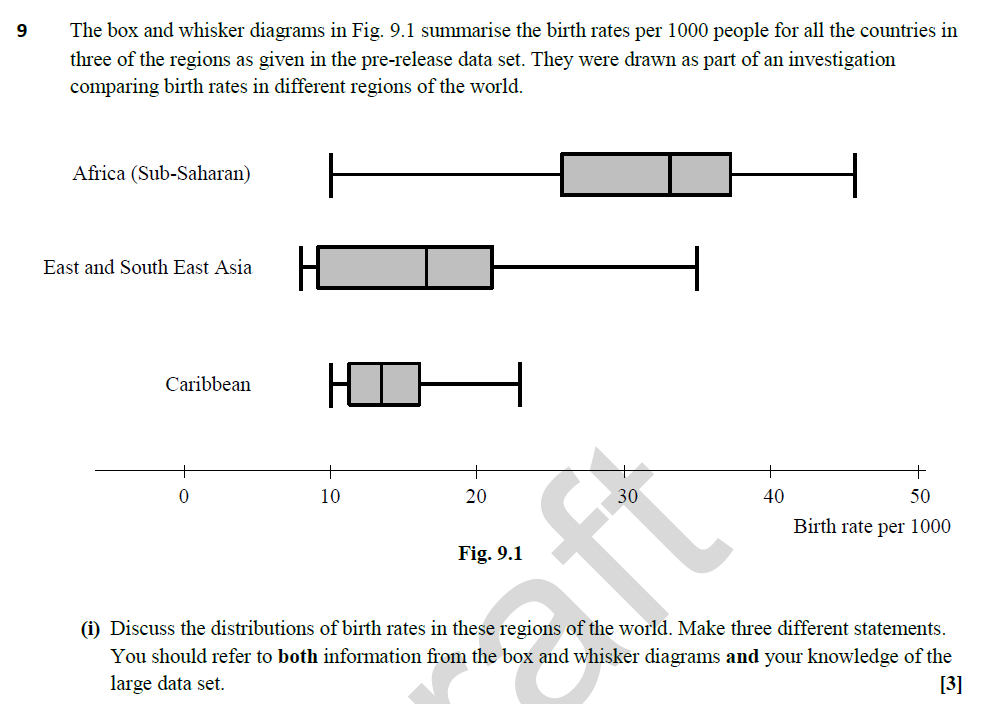
MEI Large Data set sample question
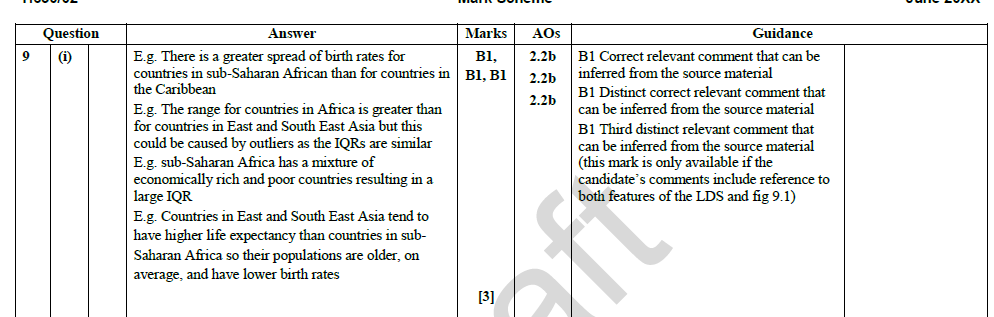
MEI Large Data Set sample question answer
UPDATE 6/1/18 Click here for Large Data Sets Acitivities
3 Comments